
Common

![]()
![]()
![]()

Commonly usable classes without dependencies.
common-collection
Contains specialized collection classes.
common-function
Contains additional functional interfaces:
- Consumers with more arguments:
TriConsumerQuadConsumer
- Functions with more arguments:
TriFunctionQuadFunction
- Throwing variants of common functional interfaces:
ThrowingConsumerThrowingFunctionThrowingRunnableThrowingSupplier
common-test
Contains a specialized testing framework for exhaustive state-space exploration. See the common-test README for a detailed user guide.
ExploratoryTestRunner: Exhaustively explores anExplorablemodel by applying@Actionand verifying@Assertionannotations. Features include:- State Pruning: Aggressively deduplicates explored states for performance.
- History-Based Pruning: Optional
historyDepthparameter to detect bugs hidden by logical state equality (the "Hidden State" problem). - Path Bounding: Supports
maxDepthto ensure termination in unbounded state spaces.
Highlights
Exploratory Testing
The ExploratoryTestRunner provides a simple but powerful way to perform Exhaustive State-Space Exploration
on any Java model. By defining actions and assertions on an Explorable implementation, the runner
systematically explores all reachable states up to a certain depth.
Key features:
- Deterministic and Exhaustive: Unlike random testing (PBT), it tests every possible sequence of actions, ensuring no edge case is missed within the search depth.
- Automatic State Pruning: Uses
snapshot()to identify states it has already visited, avoiding redundant exploration and allowing it to test millions of paths with minimal effort. - Shortest Path Guarantee: Because it uses Breadth-First Search (BFS), the first time a bug is found, the reported action sequence is guaranteed to be the shortest possible reproduction path.
- JUnit 5 Integration: Leverages standard JUnit annotations like
@ValueSource,@EnumSource, and@MethodSourceto parameterize actions.
public class MyModel implements Explorable {
private final List<String> expected = new ArrayList<>();
private final List<String> list = new MyList<>();
@Action
@ValueSource(strings = {"A", "B"})
public Runnable add(String s) {
expected.add(s); // Update expectation
return () -> list.add(s); // Perform effect
}
@Assertion
public void check() {
assertThat(list).isEqualTo(expected);
}
@Override
public Object snapshot() {
return new ArrayList<>(expected);
}
}
// Explore all paths up to depth 6
ExploratoryTestRunner.explore(MyModel.class, MyModel::new, 6);
org.int4.common.collection.ShiftList
ShiftList is a high-performance, general-purpose List and Deque implementation optimized for
use cases where frequent insertions and removals occur near the head or tail of the list. It combines
the performance benefits of block-based storage with a rotating offset mechanism to avoid costly
element shifts typical of ArrayList.
Why ShiftList?
Standard Java collections like ArrayList and LinkedList trade off insertion/removal speed,
memory locality, and access time:
-
ArrayListprovides fast indexed access but performs progressively worse when inserting or removing elements further from the end, due to the need to shift elements. -
LinkedListallows efficient insertions/removals at both ends but has poor cache performance and slow random access. -
ShiftListis designed to support fast insertions and removals at any index (especially at the head and tail) while maintaining random access performance comparable toArrayList.
Key Design Concepts
-
Block-based storage: The list is internally divided into fixed-size blocks within a contiguous array. Block size is dynamically determined based on capacity, and tuned for optimal performance.
-
Block rotation: Instead of shifting elements on every insert/remove, blocks are rotated, with only overflow elements moved between them. This make structural modifications proportional to the number of affected blocks, not the total element count.
-
Global rotation: A global rotation offset enables fast modifications near the list's start, effectively halving the number of affected blocks. Operations near the head or tail are close to
O(1), while those nearer to the middle degrade gradually toO(n/b)wherebis the block size used.
Benchmark Summary
All benchmarks were performed using JMH. For raw data see the benchmarks folder.
The lists compared are JDK's ArrayList, LinkedList, and Apache Commons Collections' TreeList.
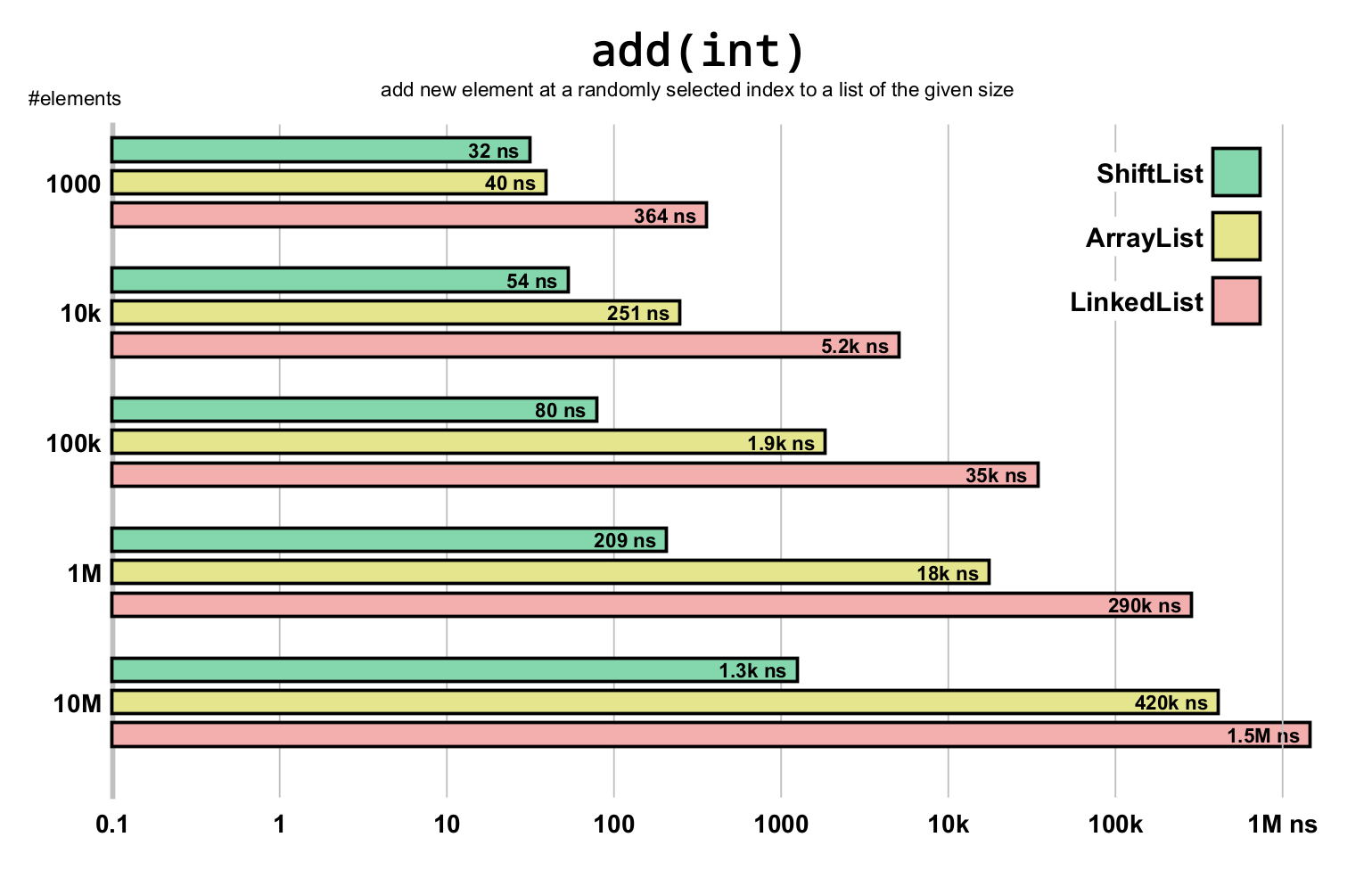
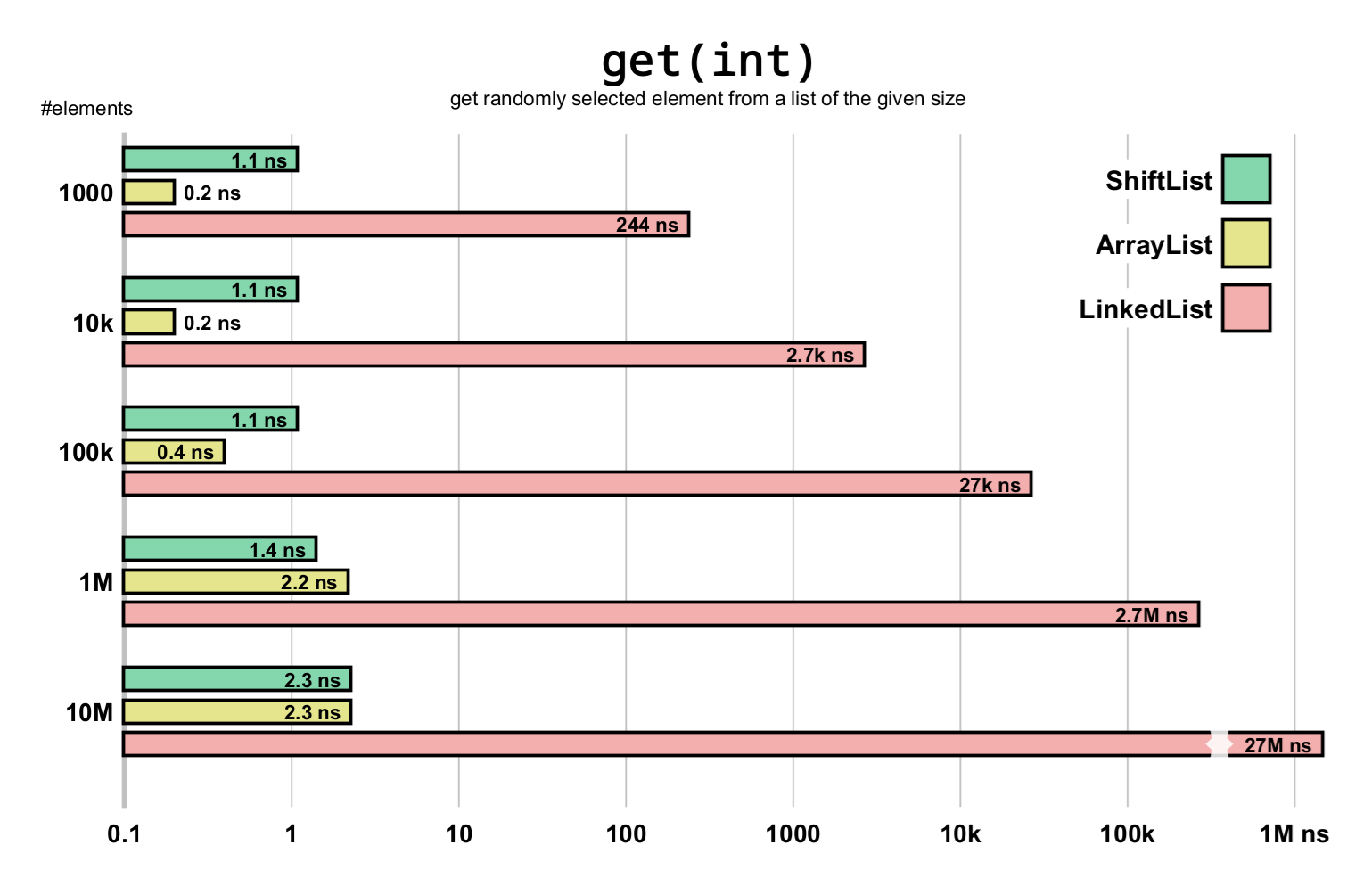
Insertions and removals
Measurements were done performing exactly 10,000 operations per iteration. For smaller lists, several
lists were used to not exceed 0.5 * size elements added per list. The resuls are in nano seconds per
element. Bolded results are fastest or within 10% of fastest.
| Operation | Size | ShiftList | ArrayList | LinkedList | TreeList |
|---|---|---|---|---|---|
| Add First | 1,000 | 2.4 ns | 54.8 ns | 2.3 ns | 57.2 ns |
| Add First | 100,000 | 2.4 ns | 3,656.5 ns | 1.8 ns | 107.9 ns |
| Add First | 10,000,000 | 3.5 ns | (*) - | 3.8 ns | 134.1 ns |
| Add Last | 1,000 | 2.2 ns | 2.6 ns | 2.3 ns | 54.5 ns |
| Add Last | 100,000 | 2.3 ns | (**) 5.0 ns | 1.8 ns | 97.0 ns |
| Add Last | 10,000,000 | 3.7 ns | 3.9 ns | 3.9 ns | 140.0 ns |
| Add Random | 1,000 | 32.4 ns | 40.5 ns | 364.5 ns | 60.7 ns |
| Add Random | 100,000 | 80.6 ns | 1,905.4 ns | 34,570.5 ns | 284.7 ns |
| Add Random | 10,000,000 | 1,263.7 ns | 419,777.2 ns | (*) - | 1,517.1 ns |
| Remove First | 1,000 | 1.8 ns | 38.7 ns | 1.7 ns | 34.8 ns |
| Remove First | 100,000 | 1.7 ns | 3,191.3 ns | 1.8 ns | 99.0 ns |
| Remove First | 10,000,000 | 2.3 ns | (*) - | 2.6 ns | 113.7 ns |
| Remove Last | 1,000 | 1.6 ns | 0.3 ns | 1.7 ns | 36.9 ns |
| Remove Last | 100,000 | 1.6 ns | 0.6 ns | 1.7 ns | 84.7 ns |
| Remove Last | 10,000,000 | 2.2 ns | 1.1 ns | 2.0 ns | 140.0 ns |
| Remove Random | 1,000 | 24.8 ns | 29.0 ns | 164.0 ns | 50.2 ns |
| Remove Random | 100,000 | 94.4 ns | 1,596.7 ns | 25,125.0 ns | 323.2 ns |
| Remove Random | 10,000,000 | 1,923.8 ns | 399,569.4 ns | (*) - | 1,423.9 ns |
(*) Timed out (max 1 minute per test)
(**)ArrayListdoes a re-allocate at 106,710 elements which skewed these results a bit
Reading
| Operation | Size | ShiftList | ArrayList | LinkedList | TreeList |
|---|---|---|---|---|---|
| Get Random | 1,000 | 1.1 ns | 0.2 ns | 243.6 ns | 34.6 ns |
| Get Random | 100,000 | 1.1 ns | 0.4 ns | 26,924.8 ns | 121.9 ns |
| Get Random | 10,000,000 | 2.3 ns | 2.2 ns | (*) - | 658.8 ns |
| Get Sequential | 1,000 | 0.7 ns | 0.1 ns | 228.0 ns | 9.2 ns |
| Get Sequential | 100,000 | 0.7 ns | 0.1 ns | 27,226.6 ns | 37.6 ns |
| Get Sequential | 10,000,000 | 0.7 ns | 0.1 ns | (*) - | 43.6 ns |
(*) Timed out (max 1 minute per test)
Time complexity
| Operation | ShiftList | ArrayList | LinkedList | TreeList |
|---|---|---|---|---|
| Add/remove at tail | O(1) |
O(1) |
O(1) |
O(log n) |
| Add/remove at head | O(1) |
O(n) |
O(1) |
O(log n) |
| Random access | O(1) |
O(1) |
O(n) |
O(log n) |
| Add/remove at index | O(n/b) |
O(n) |
O(n) |
O(log n) |
Where
nis the number of elements the list holds, andbis the block size ofShiftList
ShiftList provides performance close to ArrayList for the common get(int) operation due to minimal
indirection when locating an element. In contrast, LinkedList and TreeList require pointer traversal,
which incurs higher actual latency than their asymptotic complexity suggests.
| Feature | ShiftList | ArrayList | LinkedList | TreeList |
|---|---|---|---|---|
| Memory locality | ++ | ++ | -- | -- |
| Estimated memory/element | 4-8 bytes | 4-6 bytes | ~24 bytes | ~32 bytes |
LinkedList and TreeList allocate a wrapper object per element, leading to high memory overhead
and poor memory locality due to non-contiguous storage. ShiftList stores elements in contiguous
blocks, improving cache performance. Its capacity is always a power of two, and in the worst case
(50% utilization), memory usage is approximately 8 bytes per element. By contrast, ArrayList
typically grows by 50% when resizing and can trim to fit, leading to more compact memory usage when
fully utilized.
Limitations
ShiftListhas a minimum capacity of 16 elementsShiftListhas a maximum capacity of 2^30 - 65536 elements (this is due to the restriction that its storage array must be a power of 2 in size, and that its first and last element can't be in the same block.)